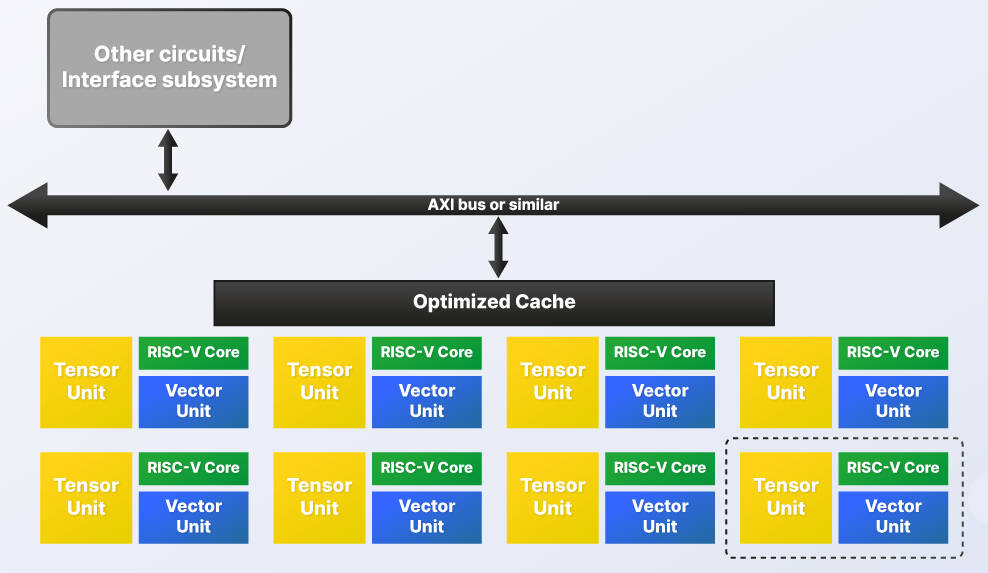
Rather than having on the same IC a multi-core CPU, a multi-core GPU for vector processing and a multi-core neural processor for tensor processing, it is advocating multiple instances of a block consisting of one out-of-order 64bit RISC-V CPU, one (GPU-like) out-of-order RVV1.0 vector unit with 4 to 32 FMAC sub-units, and one (NPU-like) tensor unit for BF16, FP16 and INT8 data scaling between , 0.25 and 2Top/s (8bit).
“The data is in the vector registers and can be used by the vector unit or the tensor unit with each part simply waiting in turn to access the same location as needed,” said Semidynamics CEO Roger Espasa. “Thus, there is zero communication latency and minimised caches.”
To this it adds its own bus technology capable of sustained DRAM access “beyond 50byte/cycle”.
“The tensor unit provides the matrix multiply capability for convolutions, while the vector unit, with its general programmability, can tackle any of today’s activation layers as well as anything the AI software community can dream of in the future,” according to the company. “As many of these processing elements as required to meet the application’s needs can be put together on a single chip. There is just one IP supplier, one RISC-V instruction set and one tool-chain.”
It sees the architecture scaling between 0.25Top/s and hundreds of Top/s, and said that it scores 33.03frame/s on the Yolo benchmark at 1GHz with one of the company’s ATV4 RISC-V cores, plus a vector unit, plus a bf16 tensor unit.
A ‘configurator’ tool is available to propose an appropriate balance of tensor and vector units.
How can tasks be split across multiple processing units?
“For AI tasks, the ONNX RunTime is capable of splitting the computation across many AI Elements,” the company told Electronics Weekly. “For other domains, such as high-performance computing, standard compiler parallelising technology – openMP or MPI – can be used to split the work.”
Hypervisor Support for containerisation and crypto-processing will be available.
Get more details on stand 5-337 at Embedded World next week in Nuremberg.