It is designed to help development teams create far-field, voice-to-machine communications functionality that is more natural and robust than available today, says Jim Beneke, vice president, engineering and technology at Avnet. He adds: “This versatile technology not only solves the problem of cancelling noise, echo and reverb that often confuse many popular cloud-based digital assistants and robotics applications, but the ability to recognise more than one wake word/phrase is a true differentiator”.
Aaware’s Acoustically Aware sound capture algorithms, paired with TrulyHandsfree wake word detection technology from Sensory, allow systems to adapt to differing noise interference, without requiring calibration for different environments or integration of the reference signal.
As a result, manufacturers can develop products with always-listening speech recognition capabilities, even in noisy environments.
“Providing customers with scale and flexibility, coupled with powerful edge acceleration for the voice-enabled artificial intelligence (AI) application market, is compelling,” said Yousef Khalilollahi, vice president, core vertical markets, Xilinx. “We see tremendous opportunity accelerating at the edge with Xilinx All Programmable SoCs and Aaware technology, enabling voice assistants, robotics and other AI-related applications”.
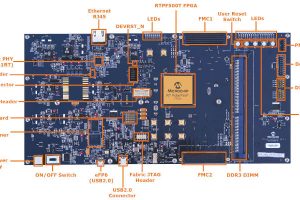
Standard sound capture platforms typically offer only fixed microphone array configurations. The Aaware platform has a concentric circular array of 13 microphones that can be configured in different combinations, allowing for performance tuning. The Aaware platform separates source speech (wake word) and follow-on speech from interfering noise with low distortion, allowing the system to integrate with third-party speech and natural language engines. Source localisation data can be forwarded to downstream applications, such as video, for multi-sensor AI applications, including those for industrial robotics and surveillance.