This accelerator appeared in a product a month later
The foreseen robot needs conventional processing for planning and control, alongside AI processing at ~100Top/s peak for vision-based environmental recognition, with low power dissipation to avoid the need for a fan – consumption of the 14nm IC is ~5W.
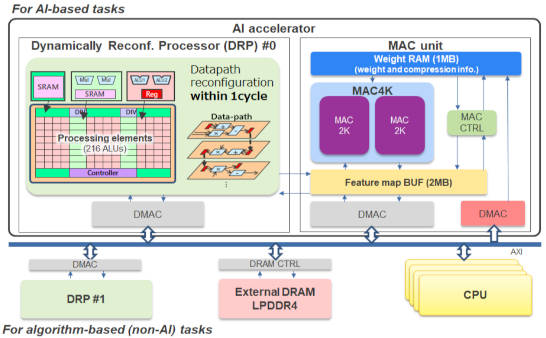
A heterogenious microprocessor architecture was chosen, that includes a dynamically reconfigurable AI accelerator that can deliver 130Top/s at 23.9Top/s/W (from 0.8V) with INT8 (8bit integer) data.
“It was measured by using an ideal CNN model – not an actual model – consisting of a single convolution layer with maximum sparsity,” the company told Electronics Weekly. “With actual AI models – ResNet50, YOLOV2 and deeplabV3 – we obtained 9-11Top/s/W.”
The difference is because this processor dynamically prunes away calculations with zeros in the weight matrix – it’s architecture allows it to perform more efficient ‘unstructured’ pruning while retaining parallel computation. Renesas calls it ‘N:M pruning’, and it results in 80 – 90% fewer calculations where many weights are zero – a ‘sparse matrix’ – while performance drops to ~8Top/s for fully dense matrices where all weights are non-zero.
Its processor has 216 processing elements, which can be reconfigured within one clock cycle, allowing the hardware to be optimised for each step of a multi-step algorithm.
“For example, SLAM [simultaneously localisation and mapping] requires multiple programming processes for robot position recognition in parallel with environment recognition by vision AI processing,” according to the company. “Renesas demonstrated operating this SLAM through instantaneous program switching with the dynamically reconfigurable processor and parallel operation of the AI accelerator and CPU, resulting in about 17 times faster operation speeds and about 12 times higher operating power efficiency than the embedded CPU alone.”
According to the company, this technology is destined for its RZ/V series of microprocessors for vision applications.
ISSCC 2024 paper 20.3: A 23.9TOPS/W @ 0.8V, 130TOPS AI accelerator with 16× performance-accelerable pruning in 14nm heterogeneous embedded MPU for real-time robot applications
ISSCC, the annual International Solid-State Circuits Conference in San Francisco, is the world’s shop window for circuit advances aimed at ICs – Attendees are exposed, literally, to the state-of-the-art.
Image credit: ISSCC 2024 Renesas