The Alveo accelerator card was launched by Xilinx last year
Machine learning algorithms, such as classification and clustering techniques, have gained significant traction in recent years because they are vital to many real-world problems.
One of the most important algorithms used for similarity search is K‑nearest neighbour (KNN) which is widely adopted for predictive analysis, text categorisation and image recognition.
It has a high computation cost, however. In the era of big data, modern datacentres adopt this specific algorithm with approximate techniques to compute demanding workloads every day. Despite this, a significant computation and energy overhead is still produced with the billion-scale nearest neighbour queries.
The team at National Technical University of Athens (NTUA) deployed a hardware accelerated approximate KNN algorithm built upon the popular Facebook artificial intelligence similarity search (FAISS) framework using FPGA platforms. The experiments were done on the Xilinx Alveo U200 FPGA card (pictured) which achieved up to 115× accelerator speed-up when compared with a single‑core CPU, the researchers report.
Big data
The new age of big data requires a trillion – even a quintillion – bytes of data to be processed every day. Emerging applications in the cloud are constantly learning from large scale data in all kinds of real‑world problems, such as data analytics and internet media. This large computational complexity motivates efforts to accelerate these tasks using hardware‑specific optimisations by employing different architectures such as CPUs, GPUs and FPGAs.
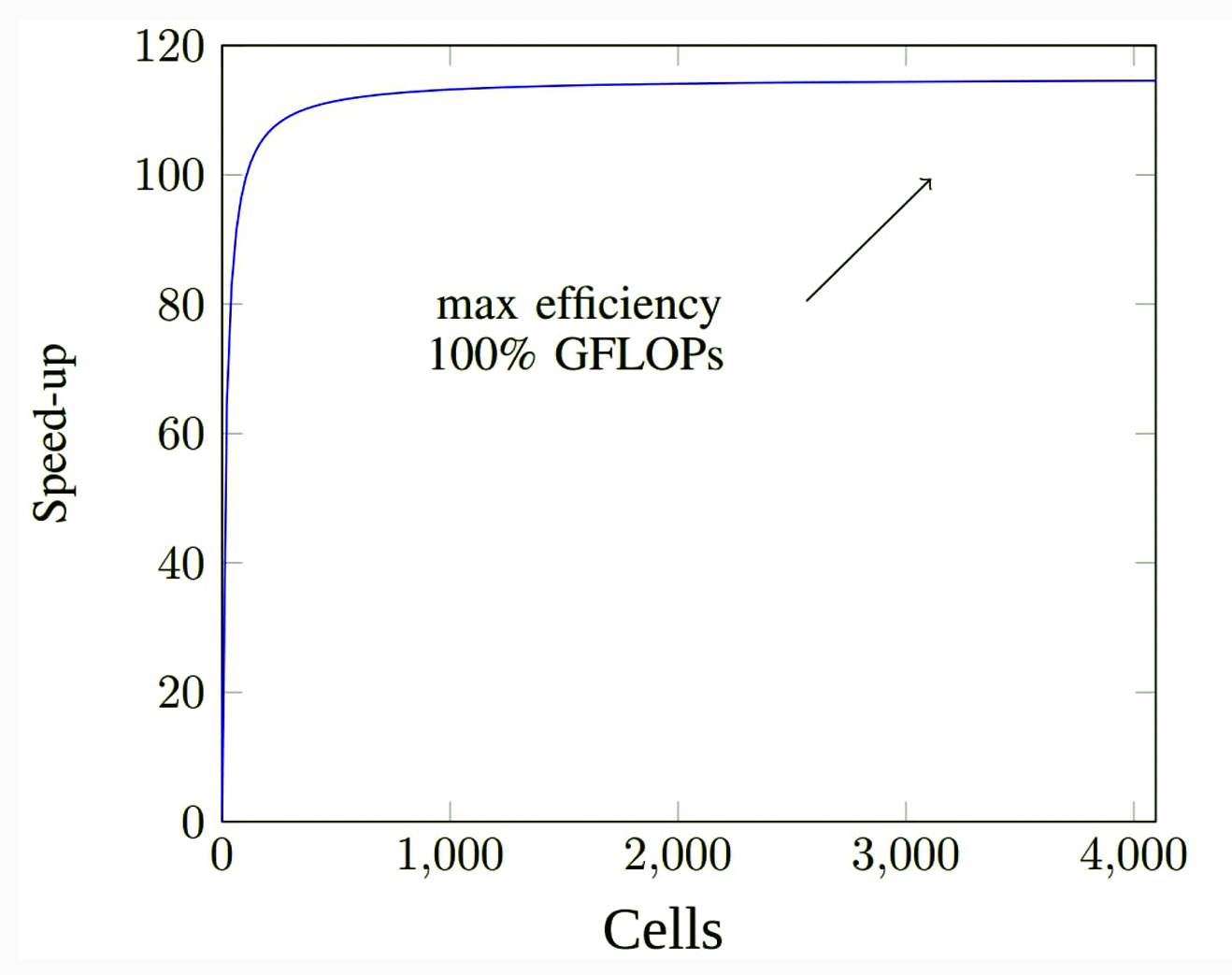
Figure 2: Random data was generated to test the acceleration for a number of cells
The growing demand for efficient and fast processing in recent years can be addressed by heterogeneous computing systems such as FPGAs. This architecture is highly parallelisable and reconfigurable, and can be mapped well to classification or clustering problems, which are usually repetitive, such as KNN. Specifically, datacentres tend to search for efficient routes to high performance and low energy cost solutions, and FPGAs play a major role in this evolution.
For example, a growing number of Microsoft services, such as the Bing search engine, use Azure’s FPGA platform. It is used most recently to accelerate a generation of ‘intelligent’ answers that include auto‑generated summaries from multiple text sources using machine reading comprehension.
“We built a very aggressive FPGA implementation, so we could really drive up the performance and the size of models we can deploy and then be able to serve it at low latency but at a great cost structure too”, researcher and Microsoft distinguished engineer Doug Burger told online publisher Data Center Knowledge.
KNN search in datacentres is characterised by large scale datasets and many times high dimensional inputs. Even very modern high performance computers cannot handle these requests, resulting in a computer phenomenon known as the curse of dimensionality.
The approximate nearest neighbour (ANN) algorithm overcomes the large workload that casual KNN demands in terms of arithmetic complexity and/or high data bandwidth by implementing a partial query search. There is still a substantial workload needed for training big datasets before proceeding with query searches.
For example FAISS uses index building algorithms for implementing approximate KNN but the NTUA team concluded that this is very time consuming and therefore energy inefficient, especially when frequent retraining is needed, due to the need to handle statistically different data.
Training forms optimisation
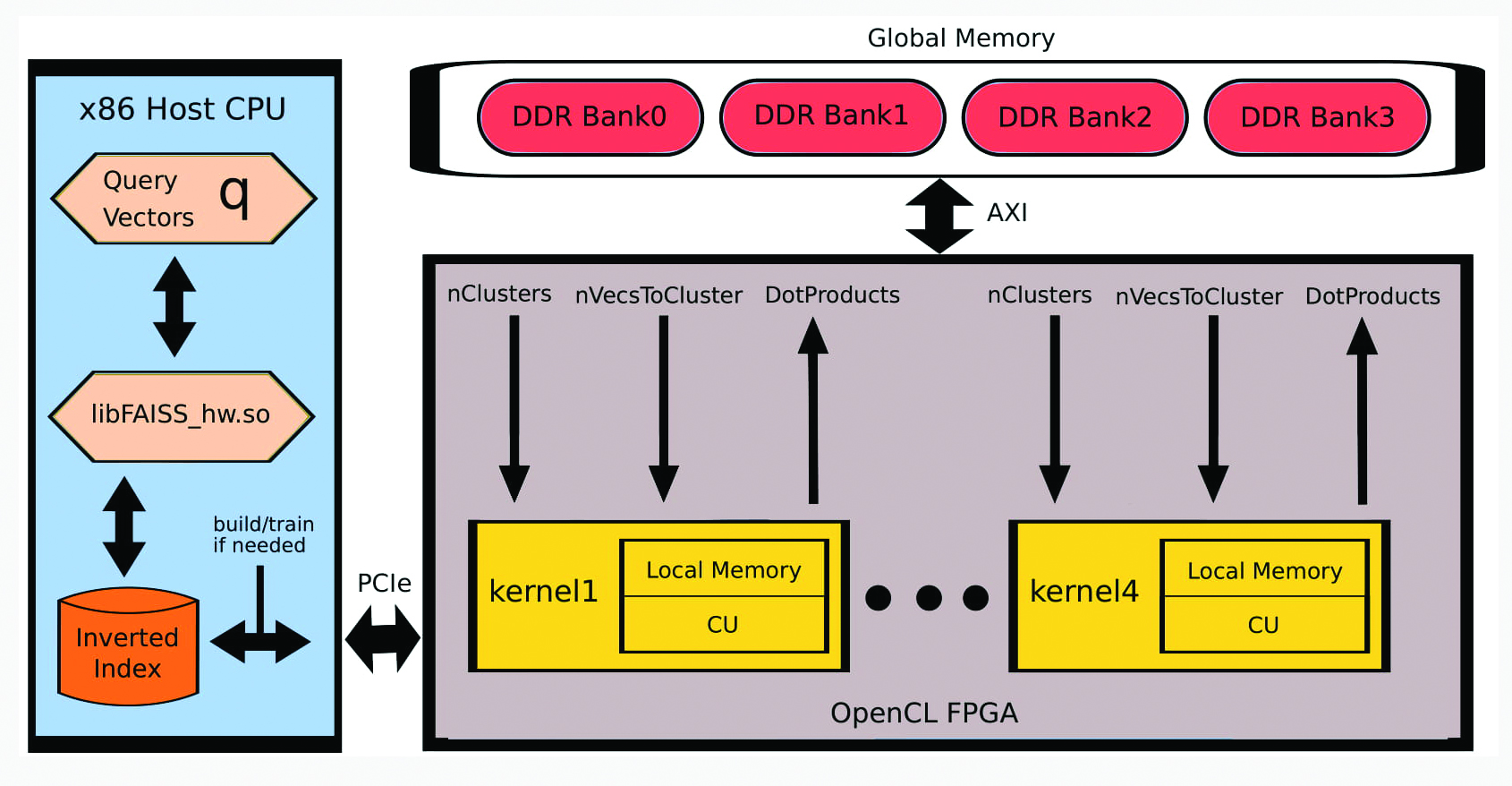
Figure 1: Schematic of the Alveo U200 data flow
The FAISS algorithm used to speed up KNN queries uses specific indexing techniques so that thousands of vectors can be searched without accessing all the dataset, just a part of it. This is because exact results are impractical on billion-sized databases, so new techniques that index or even compress the vectors with quantisation methods have been introduced and used by many cloud companies.
FAISS constructs the Inverted File index by defining data cells. During training each database vector falls in one of these cells. Then at search time, only the database vectors contained in the cell to which the query is mapped (along with a few neighbouring ones) are compared against the query vector.
The training algorithm contains many multiply‑accumulate (MAC) operations, specifically matrix multiplication functions, so it is common for these algorithms to be mapped for hardware parallelisation through the FPGA.
Figure 1 illustrates the general dataflow of the whole application where FAISS operates seamlessly in the host CPU which is an x86 Linux system. When it needs to be trained in or build an index it communicates through PCIe with the Alveo U200, sending and receiving the necessary information.
In order to maximise data throughput a 512-bit user interface was implemented on each kernel side; this is the maximum memory bandwidth supported in the FPGA using OpenCL vector datatypes.
Along with the use of all four double data rate (DDR) registers of the device for read-write operations it achieved optimal memory transfer rates between host-DDRs and DDRs-kernels. Four identical kernels, operating simultaneously, were optimised with fine grained parallelism and distributed the workload evenly. This accelerator on the FPGA speeded up the throughput 115 times compared with the performance of a single-core CPU.
Figure 2 shows random data generated to test the acceleration for various numbers of cells. The implementation achieves up to 4x vs a 36-thread Xeon on the end-to-end execution of FAISS.
It is worth noting that the research team also ported and tested the application on Amazon Web Service (AWS) cloud, running it on a similar FPGA in the cloud, the VU9P. This has a similar price tag on Amazon (price/hour) to the 36-thread Xeon CPU that was tested here.
From this, we can conclude that the proposed FPGA design can have a practical use for the industry, as it has better performance while keeping the power consumption low.
The future for accelerators
Hardware accelerators look to be a promising solution for the increase of the performance and power efficiency in machine learning applications. The main challenge, though, is the programming efficiency, where many frameworks such as FAISS do not support the transparent use of FPGA acceleration modules.
The quantitative and qualitative comparison shows that the proposed hardware accelerator can outperform a 36-thread Xeon CPU. Hardware/software co-design is a valid solution, especially for the cloud computing workloads, in this case for similarity search algorithms.
Performance and power efficiency play a major role to meet the constantly increasing workload demands in the cloud. Companies can make use of heterogeneous cloud computing services and, in many cases, prefer FPGAs for high performance and low power solutions for a variety of tasks.